오늘 포스팅에서는 apply 메서드를 사용해 groupby 객체에 함수를 적용하는 방법을 알아보겠습니다.
apply 메서드는 groupby 메서드 중에서도 가장 일반적인 메서드입니다. 작동하는 방식은 다음과 같습니다.
- 먼저 객체를 여러 조각으로 나눕니다.
- 그리고 전달된 함수를 각 조각에 일괄적으로 적용합니다.
- 마지막으로 이를 다시 합칩니다.
글로만 봐서는 이해가 잘 되지 않으니 예시를 통해 살펴보겠습니다. 지난 포스팅링크에 이어 오늘도 팁 데이터셋을 불러오겠습니다.
데이터셋 불러오기
tips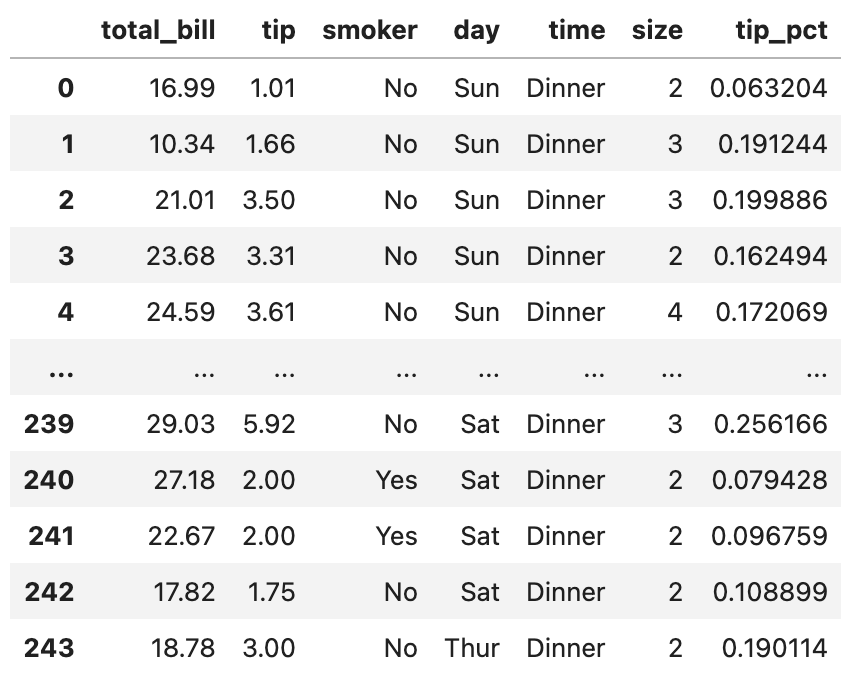
이 데이터셋에서 그룹별로 상위 5개의 tip_pct 값을 골라내 봅시다.
우선 특정 열에서 가장 큰 값을 갖는 상위 n개 행을 선택하는 함수부터 작성해 보겠습니다.
함수 작성하기
def top(df, n=5, column="tip_pct"):
return df.sort_values(column, ascending=False)[:n]
top(tips)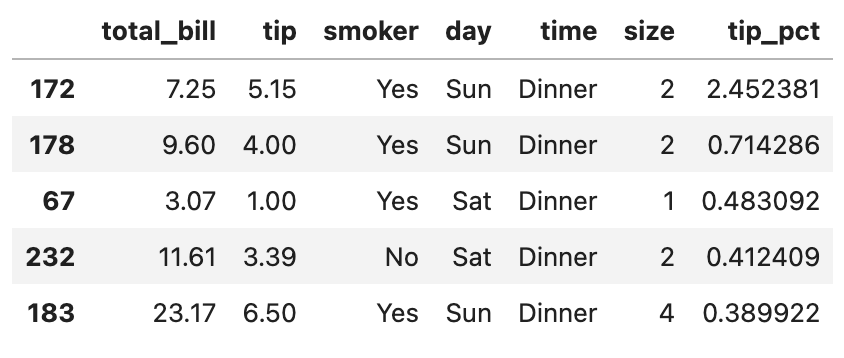
top 함수를 정의하고 tips 데이터셋에 적용한 결과입니다. tip_pct 컬럼을 기준으로 상위 5개에 해당하는 데이터가 출력되었습니다.
이제 이 함수를 smoker 그룹에 대해 적용해 보겠습니다. 즉, smoker 그룹별로 tip_pct 상위 5개의 데이터를 추출하는 것입니다. 적용은 간단합니다.
apply 메서드로 groupby 객체에 함수 적용하기
tips.groupby("smoker").apply(top)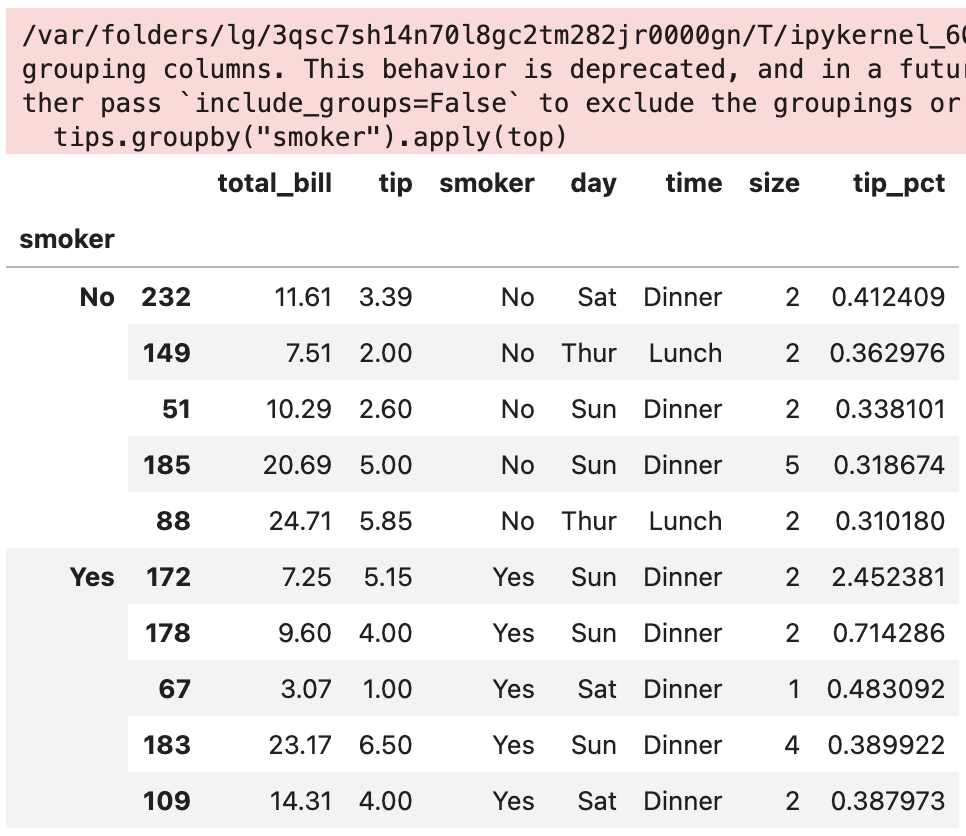
tips 데이터셋을 smoker 컬럼 기준으로 groupby한 다음, apply 메서드를 써서 top 함수를 적용한 결과입니다.
이 결과를 보면 제일 처음 설명한 apply 메서드의 작동 방식에 대해 이해할 수 있는데요.
- 먼저
tips데이터프레임이smoker값에 따라 여러 그룹(조각)으로 나뉩니다. - 그리고 나뉜 데이터프레임 조각에
top함수가 일괄 적용되었습니다. - 마지막으로 2번의 결과물이
pandas.concat으로 하나로 합쳐진 뒤 그룹 이름이 붙었습니다. 따라서, 결과물은 위에서 보듯 계층적 색인을 갖게 됩니다.
이제 제일 처음 설명드린 apply 메서드의 작동 방식이 이해되셨을 겁니다.
주의) apply 메서드의 include_groups
그런데 위 결과물에서 빨간 박스 + 경고 문구가 떠 있는 게 보이시나요? 전문은 아래와 같이 되어 있습니다.
/var/folders/lg/3qsc7sh14n70l8gc2tm282jr0000gn/T/ipykernel_60117/2530541573.py:1: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
tips.groupby("smoker").apply(top)
저 경고 문안이 뜨는 이유는 groupby 객체에 연산을 수행하는 동작이 미래의 판다스 버전에서 변경될 예정이기 때문인데요.
위에서 groupby 객체에 top 함수를 apply할 때 아무 옵션도 주지 않았기 때문에, 결과물에도 그루핑의 기준인 smoker 열이 포함되어 있습니다. 하지만 미래의 판다스 버전에서는 기준 열이 자동으로 제외될 예정이므로, 사용자가 명시적으로 포함 여부를 선택해 주어야 한다는 내용입니다. 즉,
tips.groupby("smoker").apply(top, include_groups=False)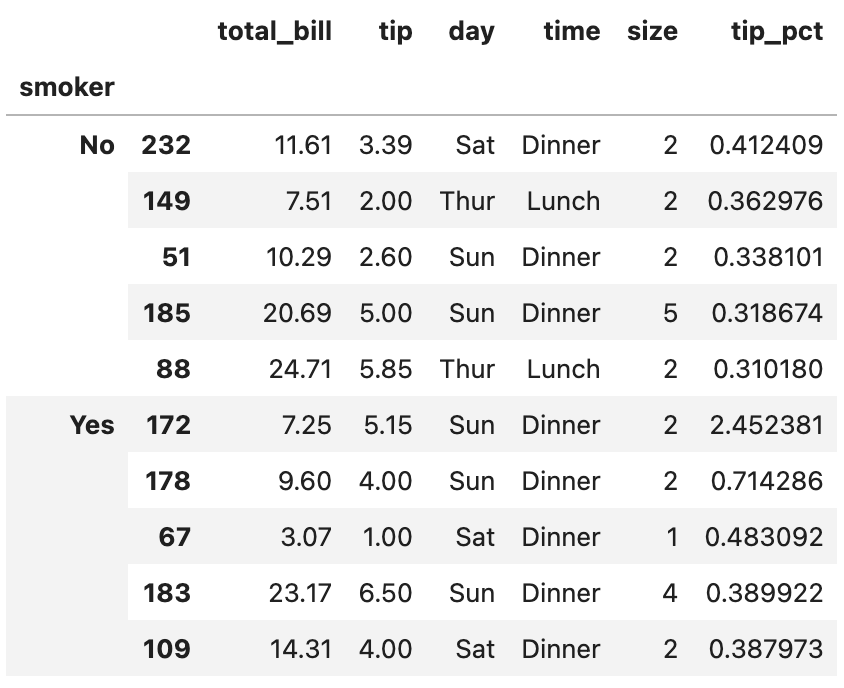
이렇게 include_groups = False 옵션을 써 주면 오류 메시지가 뜨지 않게 됩니다. 외우고 있을 필요는 없고, 그냥 ‘이런 게 있구나’ 정도로만 생각하고 넘어가겠습니다.
apply 메서드에 추가 인수나 예약어 붙이기
만약 apply 메서드에 넘길 함수가 추가적인 인수나 예약어를 받는다면 함수 이름 뒤에 붙여서 넘겨주면 됩니다.
tips.groupby(["smoker", "day"]).apply(
top, n=1, column="total_bill", include_groups=False
)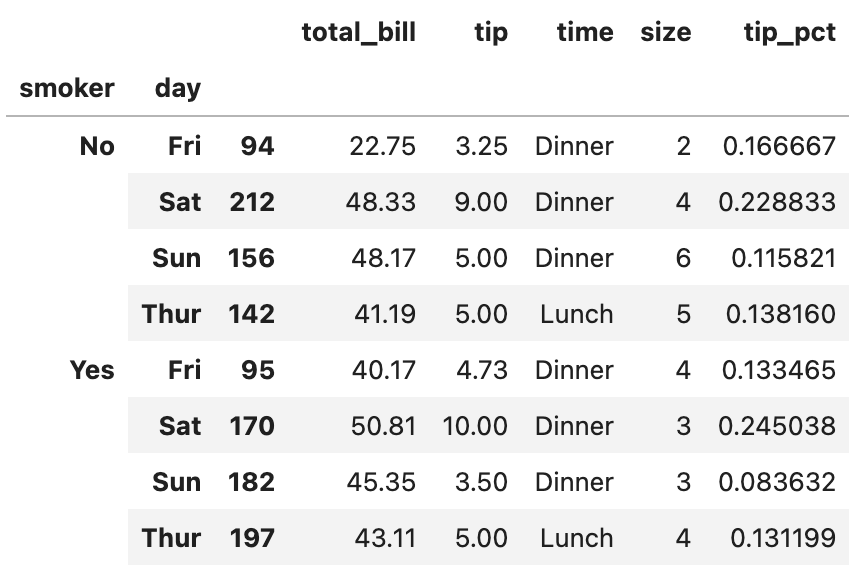
tips 데이터셋을 smoker와 day를 기준으로 그룹화한 뒤, total_bill을 기준으로 각 그룹별 1위 데이터만 뽑은 결과입니다. 이 때 헷갈리지 말아야 할 부분이 하나 있습니다.
apply 메서드가 top에 n=1, columns = total_bill을 전달한다는 점입니다. apply로 함수를 실행하긴 하지만, 함수의 기본값이 아닌 apply가 전달한 값이 적용된다는 점에 주의해야 합니다.
이번 포스팅에서 소개한 방법 외에도 apply 메서드를 활용할 수 있는 방법은 다양합니다. 다음 포스팅부터는 주로 groupby를 사용해 다양한 문제를 해결하는 방법을 알아보겠습니다.
참고 : 공식문서 링크pandas.core.groupby.DataFrameGroupBy.apply