이번 포스팅에서는 판다스 groupby 객체에서 표본 추출하기에 대해 알아보겠습니다.
어느덧 판다스와 데이터 분석 공부에 관련된 포스팅도 몇 개가 생겨서, 보시기 편하게 내부 메뉴를 개편할 예정입니다.
데이터셋으로부터 랜덤으로 표본을 뽑아내는 방법에는 여러 가지가 있는데요. 이 중에서 Series의 sample 메서드를 사용하겠습니다.
예를 들기 위해 트럼프 카드를 코드로 만들어 보겠습니다.
# 하트, 스페이드, 클로버, 다이아몬드
suits = ["H", "S", "C", "D"]
# 한 문양당 1~10까지 있고, J,Q,K는 똑같이 10으로 취급 * 문양은 총 4개
card_val = (list(range(1, 11)) + [10] * 3) * 4
# 1번은 A(에이스)로 표기 + 2~10까지는 숫자 + 그 다음은 J,Q,K
base_names = ["A"] + list(range(2, 11)) + ["J", "Q", "K"]
cards = []
# for문을 순회하면서 cards 리스트에 담기
for suit in suits:
cards.extend(str(num) + suit for num in base_names)
deck = pd.Series(card_val, index=cards)
deck.head(13)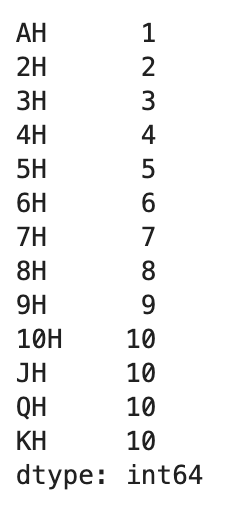
카드 이름과 값을 색인으로 하는 트럼프 카드를 Series 객체로 만들어 보았습니다. 이제 5장의 카드를 무작위로 뽑기 위해 다음 코드를 작성해 봅니다.
def draw(deck, n=5):
return deck.sample(n)
draw(deck)
스페이드 J, 클로버 2, 스페이드 3, 클로버 Q, 하트 10이 뽑혔네요.
sample 메서드는 무작위이므로 코드를 실행할 때마다 결과가 바뀝니다. 아울러 비복원추출이기 때문에 카드가 중복으로 뽑히지는 않습니다.
이제 각 문양별로 2장씩의 카드를 무작위로 뽑고 싶으면 어떻게 해야 할까요? 카드 이름의 끝 글자가 문양을 나타내므로, 이를 이용해 그룹을 나누고 apply를 이용해 보겠습니다.
def get_suit(card):
return card[-1] # 마지막 글자가 모양을 나타냄
deck.groupby(get_suit).apply(draw, n=2)
문양별로 2개씩의 카드가 랜덤으로 추출되었습니다.
이 때도 마찬가지로 draw 함수 안의 sample 메서드 때문에 코드를 실행할 때마다 결과가 바뀌는 점에 주의합시다.
만약 계층적 색인이 적용되어 있는 점이 보기 불편하다면 group_keys = false 옵션을 통해 선택된 카드만 남길 수도 있습니다. 즉,
deck.groupby(get_suit, group_keys=False).apply(draw, n=2)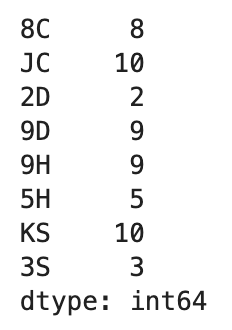
이렇게 표현할 수도 있습니다.