이번 포스팅에서는 판다스에서 groupby 객체를 만들어 데이터를 집계할 때, 함수를 적용하는 다양한 방법을 살펴봅니다.
데이터 불러오기 및 준비
먼저 예전 Velog에 올렸던 포스팅에서 사용한 적이 있는
팁(tips) 데이터셋을 다시 불러오고,tip_pct라는 컬럼까지 추가해 보겠습니다.
tips = pd.read_csv("tips.csv")
tips["tip_pct"] = tips["tip"] / (tips["total_bill"] - tips["tip"])
tips.head()
단일 열/여러 열에 집계함수 적용하기
다음으로는 day와 smoker 열을 써서 tips를 묶어봅시다.
grouped = tips.groupby(["day", "smoker"])그런 후에 특정 열만 들고 와서
집계함수를 써서 평균을 구해보겠습니다.
grouped_pct = grouped["tip_pct"]
grouped_pct.agg("mean")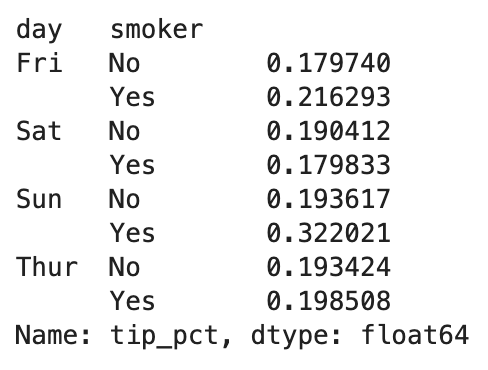
결과는 위와 같이 ‘day와 smoker로 그루핑된 결과’에 대한 평균이 나오게 됩니다. 위 결과는 단일 열에 대해 계산한 결과이므로 Series로 반환되지만, 만약 함수 목록이나 함수 이름을 넘기면 함수 이름을 열 이름으로 하는 DataFrame이 반환됩니다. 즉,
grouped_pct.agg(["mean", "std", peak_to_peak])이 코드를 실행하면

이와 같은 결과를 얻습니다.tip_pct의 평균과 표준편차가 각각 계산되었고, 결과물이 DataFrame으로 반환된 것이 보입니다. (peak_to_peak 컬럼은 최댓값과 최솟값의 차를 구하기 위해 임의로 만든 함수이고, 이 포스팅에서 만들었습니다.)
집계함수 결과를 나타낼 열 이름 지정하기
groupby 객체가 자동으로 지정한 함수 이름을 열 이름으로 쓰고 싶지 않을 경우는 어떻게 할까요? 이럴 때는 이름과 함수가 담긴 튜플의 리스트를 넘기는 것으로 해결할 수 있습니다. 이 경우, 각 튜플의 첫 번째 원소가 DataFrame의 열 이름으로 사용됩니다. 예를 들어 아래 코드를 실행하면,
grouped_pct.agg([("average", "mean"), ("stdev", "std")])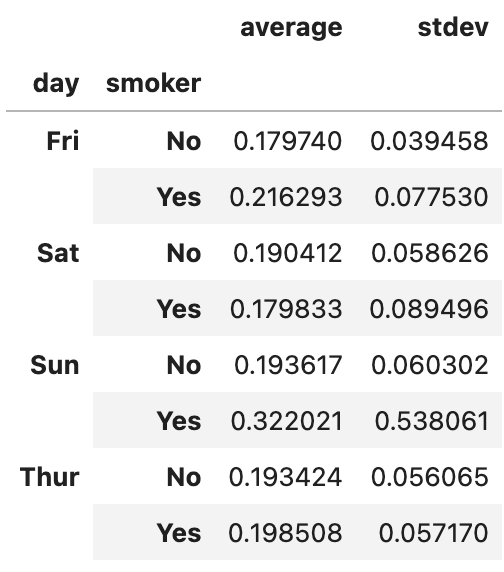
이런 결과를 얻게 됩니다.
mean이 아니라 average로, std가 아니라 stdev로 열 이름이 설정되었습니다.
여러 개의 함수를 모든 열에 적용하기
DataFrame에서 열마다 다른 함수를 적용하거나,
여러 개의 함수를 모든 열에 적용하는 것도 가능합니다.
예컨대 tip_pct와 total_bill 컬럼 각각에 세 가지 통계치를 내야 하는 상황이라고 가정하겠습니다.
functions = ["count", "mean", "max"]
result = grouped[["tip_pct", "total_bill"]].agg(functions)
result결과는 아래와 같습니다.
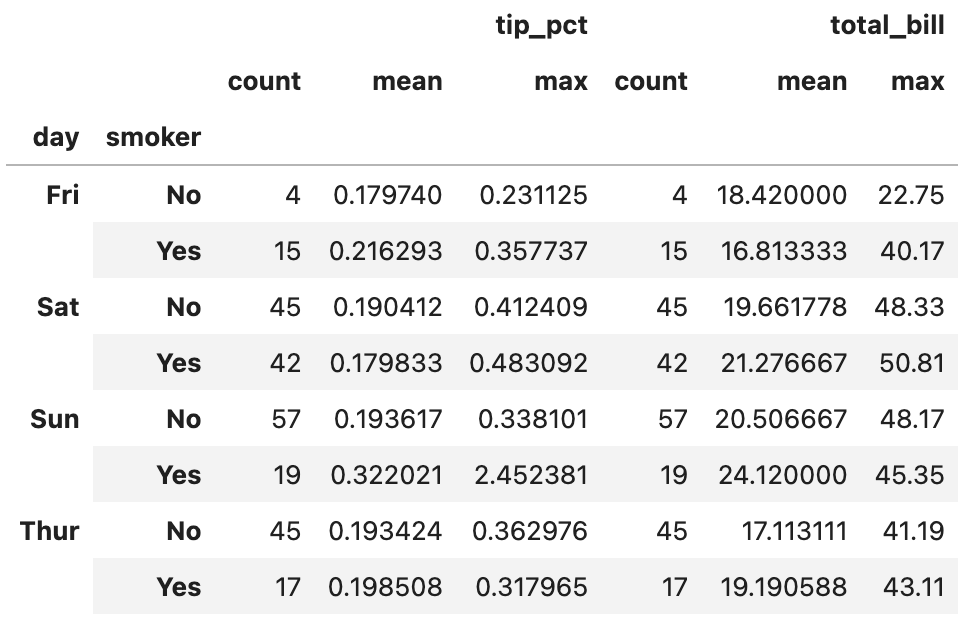
tip_pct와 total_bill 컬럼 각각에 count와 mean, max 이렇게 세 개의 함수가 적용되었습니다. 이 결과는 계층적인 열을 가지며, 각 열을 따로 계산한 다음 concat 메서드를 사용해 이어붙인 것과 동일합니다. keys 인수로 열 이름을 넘겨야겠죠.
위에서는 열 이름을 functions라는 리스트에 담아서 전달했지만,
앞에서 살펴봤던 것처럼 열 이름이 담긴 튜플 리스트를 넘기는 것도 가능합니다. 이 경우는 아까와 마찬가지로 튜플의 첫 번째 원소가 열 이름이 됩니다. 즉,
ftuples = [("Average", "mean"), ("Variance", "var")]
grouped[["tip_pct", "total_bill"]].agg(ftuples)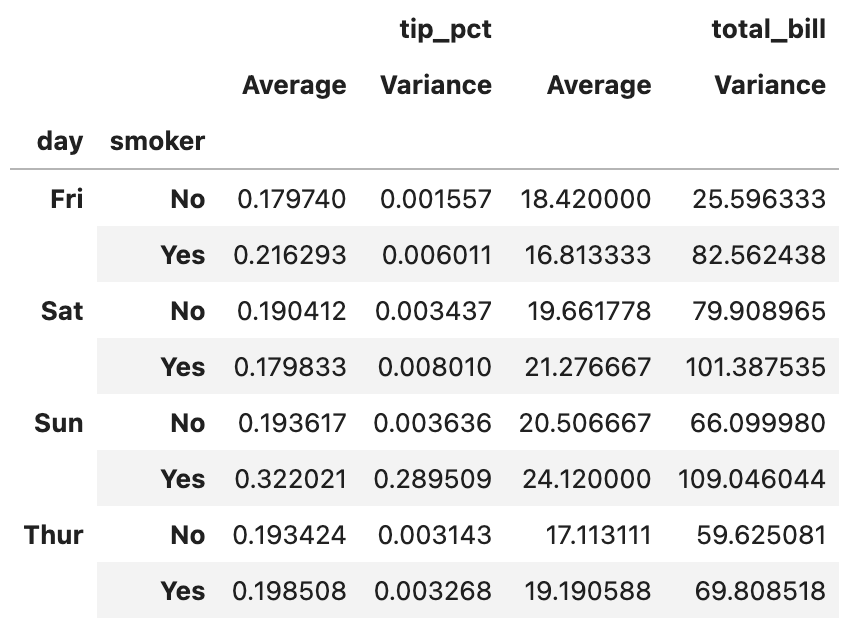
위 코드를 실행한 결과입니다.
아까처럼 튜플의 첫 원소가 열 이름으로 잘 들어가 있네요:)
열마다 서로 다른 함수 적용하기
열마다 다른 함수를 적용하고 싶다면 agg 메서드에 딕셔너리를 넘깁니다.
역시 말만 봐서는 이해가 어려우니 예시를 보겠습니다.
grouped.agg({"tip": "max", "size": "sum"})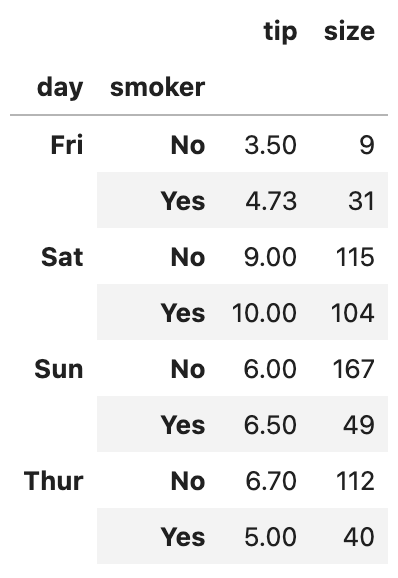
tip 열에는 그룹별 최대값이, size 열에는 그룹의 합계가 적용되었습니다.
지금 예에서는 tip과 size 컬럼에 각각 한 개씩의 서로 다른 함수가 적용되었는데요. 만약 한 쪽 컬럼에 여러 개의 함수가 적용되면 어떻게 될까요?
grouped.agg({"tip_pct": ["min", "max", "mean", "std"], "size": "sum"})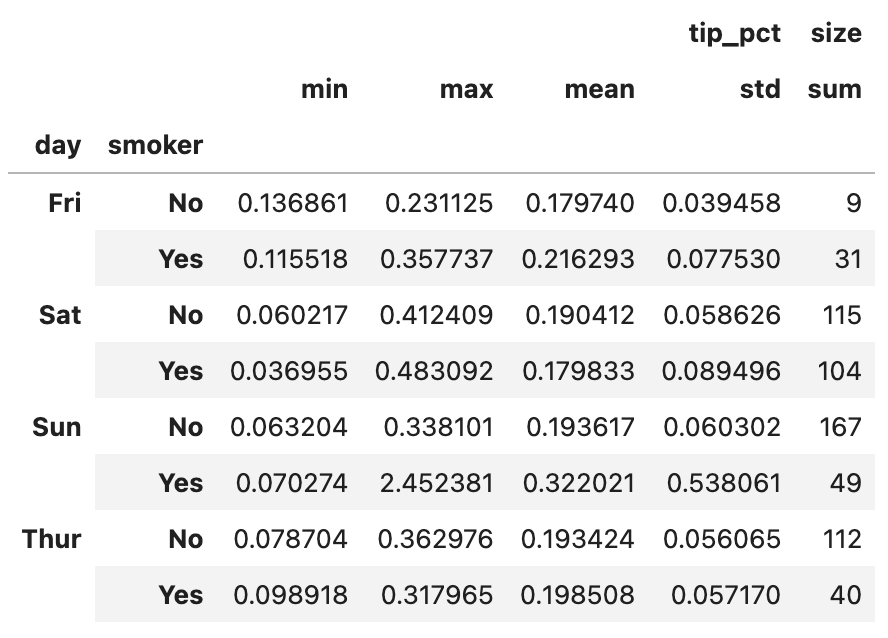
결과는 위와 같습니다. 단 하나의 열에라도 여러 개의 함수가 적용된다면 (위의 예에서는 tip_pct) 데이터프레임은 계층적인 열을 갖습니다.