지난 포스팅링크에서는 groupby로 집계한 데이터의 열에 여러 가지 함수를 적용하는 방법에 대해 알아봤습니다.
그런데 모든 그루핑의 결과물이 항상 유일한 키 조합을 갖고 있는 건 아니죠. 이럴 경우에는 어떻게 데이터를 처리할 수 있을까요?
먼저 지난 포스팅에서 살펴본 팁 데이터셋을 다시 불러와 보겠습니다.
이제 이 데이터셋을 day와 smoker 컬럼을 기준으로 그루핑해 보겠습니다.
grouped = tips.groupby(["day", "smoker"])
grouped
목표대로 groupby를 수행한 결과물입니다. 아직 아무 연산도 안 된 상태이므로 DataFrameGroupBy라는 객체 정보만 뜨고 있습니다.
만약 이 상태에서 곧장 컬럼별 평균을 구한다고 가정해 보겠습니다.
grouped.mean(numeric_only=True)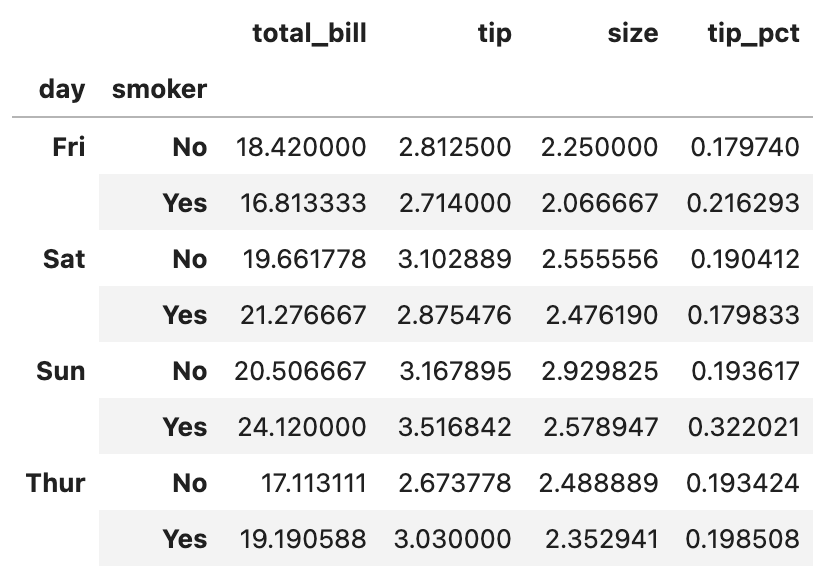
이렇게 계층적 색인이 적용된 채로 컬럼별 평균이 구해집니다. (수치형 컬럼에만 계산이 적용될 수 있도록 numeric_only를 설정해 주었습니다)
위에서 언급한 대로 색인을 원치 않을 경우에는 두 가지 방법이 있습니다.
집계를 수행하는 단계에서 색인 비활성화하기
첫 번째 방법은 집계를 수행하는 시점에서 색인을 비활성화하는 것입니다. 즉,
# 집계를 수행하는 시점에서 색인 없애기
grouped_a = tips.groupby(["day", "smoker"], as_index=False)
grouped_a.mean(numeric_only=True)이렇게 as_index = False를 써 줌으로써 색인을 비활성화할 수 있습니다. 결과는 어떻게 나올까요?
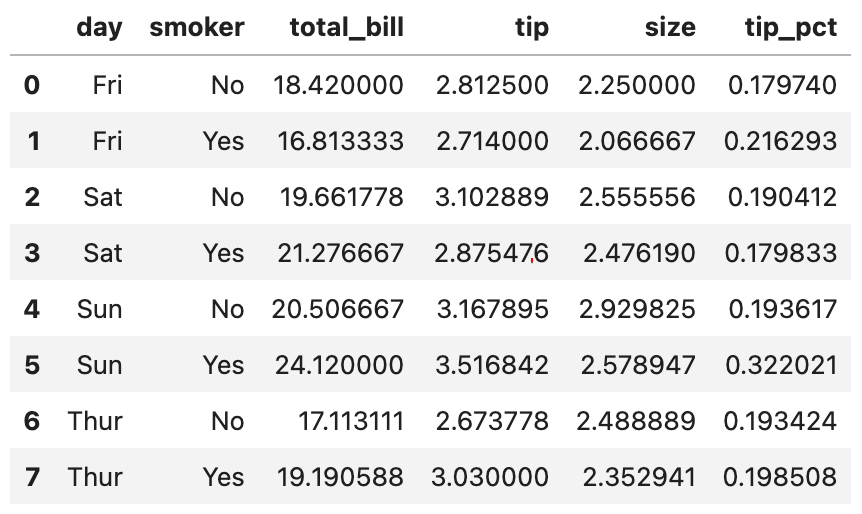
계층적 색인이 적용되지 않고 모든 행이 숫자 인덱스로 분리되어 표시되는 것을 확인할 수 있습니다.
집계가 수행된 후, 연산 단계에서 색인 비활성화하기
두 번째 방법은 집계 자체는 (이 경우 계층적 색인이 적용된 채로) 그대로 수행하되, mean과 같은 연산을 수행하면서 색인을 초기화하는 방법입니다. 코드로는 아래와 같이 표현할 수 있습니다.
# 집계는 동일하게 수행하되, 연산 단계에서 색인 초기화
grouped_b = tips.groupby(["day", "smoker"])
grouped_b.mean(numeric_only=True).reset_index()첫 번째 방법과의 차이가 느껴지시나요?
grouped_b는 groupby를 수행한 뒤, mean 연산의 결과물에 대해 reset_index()를 적용해 색인을 초기화했습니다.
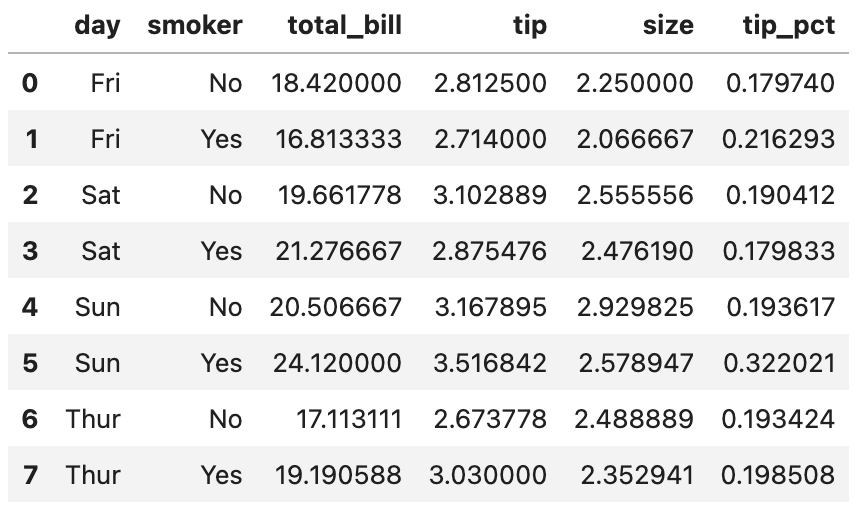
결과는 첫 번째 방법과 동일합니다.
다만, 첫 번째 방법처럼 집계를 하는 단계에서 as_index = False 옵션을 사용하면 불필요한 계산을 피할 수 있다는 장점이 있습니다. 즉, groupby 후 reset_index를 하면 두 번의 계산을 해야 하는데 비해 as_index를 쓰면 곧바로 결과가 반환되므로 조금 더 효율적일 수 있는 것이죠.