지난 포스팅링크에서는 apply 메서드의 기본적인 활용법을 살펴봤습니다. 이번 포스팅에서는 판다스의 cut과 qcut을 사용해 데이터셋을 그루핑하고, apply 메서드를 적용해 통계치를 뽑는 부분까지 다뤄보겠습니다. 예전에 다른 블로그에서 다뤘던 내용링크이기도 합니다:)
판다스에 cut과 qcut이라는 함수가 있습니다. 선택한 크기만큼, 혹은 표본 사분위수에 따라 데이터를 나눌 수 있게 해 주는 함수들인데요.
이 함수들을 groupby와 조합하면, 데이터셋에 대한 사분위수 분석이나 버킷 분석을 쉽게 수행할 수 있습니다. 예를 하나 들어보겠습니다.
frame = pd.DataFrame(
{"data1": np.random.standard_normal(1000), "data2": np.random.standard_normal(1000)}
)
frame.head()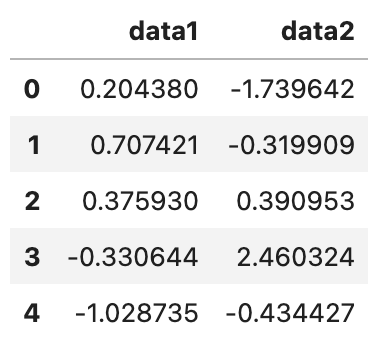
data1 열과 data2 열에 정규분포를 따르는 1,000개의 난수가 들어가 있습니다. 이제 이 데이터셋을 cut을 사용해 등간격으로 나눠 보겠습니다.
quartiles = pd.cut(frame["data1"], 4)
quartiles.head(10)
data1 컬럼을 4개의 구간으로 쪼갰습니다. 각각의 데이터값은 나타나지 않고, 어떤 구간에 속해 있는지만 표시됩니다.
이렇게 cut에서 반환된 Categorical 객체는 바로 groupby로 넘길 수 있습니다. quartiles에 대한 그룹 통계는 아래와 같이 계산합니다.
def get_stats(group):
return pd.DataFrame(
{
"min": group.min(),
"max": group.max(),
"count": group.count(),
"mean": group.mean(),
}
)
grouped = frame.groupby(quartiles, observed=False)
grouped.apply(get_stats)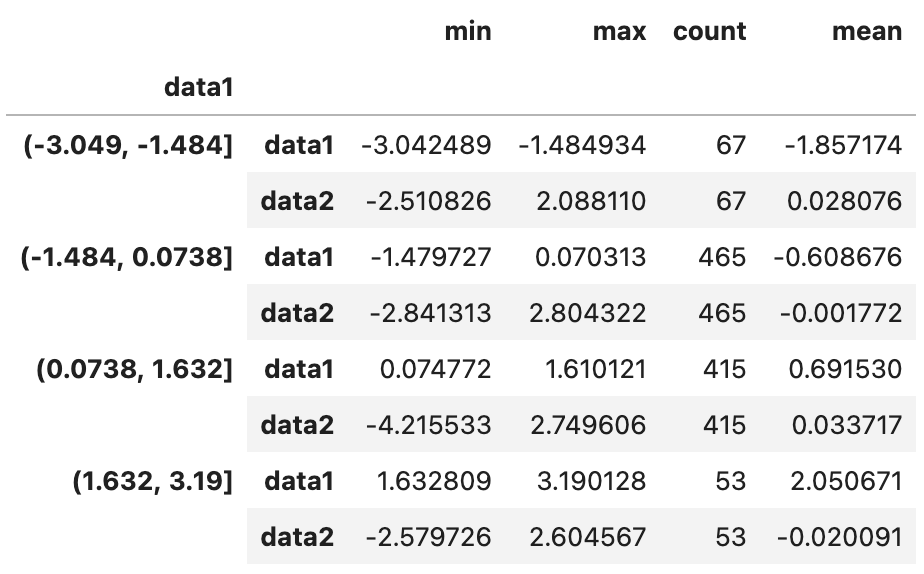
data1과 data2열 모두에 대해 구간별 통계량이 구해졌습니다. 등간격 버킷이므로 각 구간별 모수(count)는 모두 다릅니다.
grouped를 계산할 때 observed=False 옵션을 넣는 것은 다른 포스팅에서도 다룬 적이 있는데요. 쉽게 말해 데이터가 있는 범주만 결과에 포함할 것인지 여부를 묻는 옵션입니다. (앞으로는 디폴트가 observed = True로 바뀔 거라고 하네요)
등간격 버킷에 대한 통계량은 아래와 같이 좀 더 단순한 형태로 구할 수도 있습니다.
grouped.agg(["min", "max", "count", "mean"])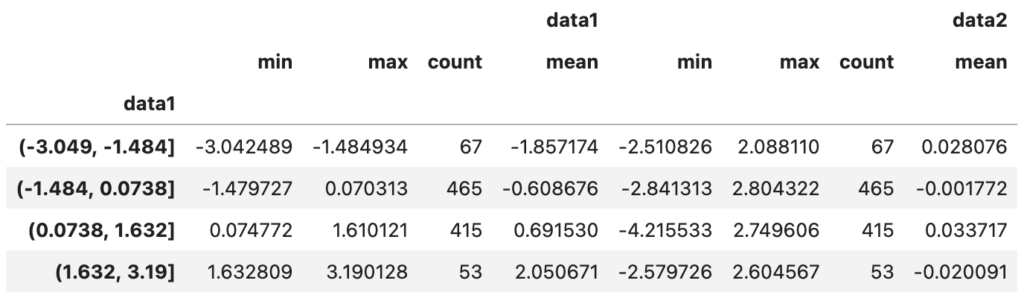
이 경우 결과는 계층적 열을 갖는 데이터프레임으로 반환됩니다.
앞서 살펴본 등간격 버킷 말고 표준 사분위수에 기반해 크기가 동일한 버킷을 계산해 보겠습니다. 이 때는 판다스의 qcut을 씁니다.
quartiles_samp = pd.qcut(frame["data1"], 4, labels=False)
quartiles_samp.head()
샘플을 사분위수로 나누기 위해 버킷 수를 4로 넘기고, labels=False를 전달해 각 사분위수 색인을 구했습니다. 앞서 cut을 수행했을 때는 데이터값 대신 어떤 구간에 속해있는지가 표시되었다면, 지금은 몇 번 버킷에 속해있는지가 표시됩니다.
grouped = frame.groupby(quartiles_samp)
grouped.apply(get_stats)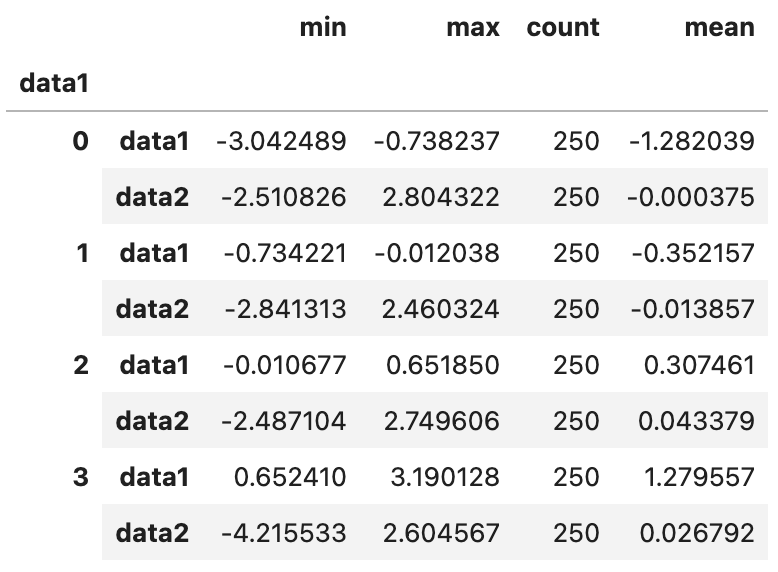
frame을 quartiles_samp를 기준으로 groupby한 다음,
다시 apply를 사용해 get_stats 함수를 적용해 준 결과입니다.
qcut을 사용해 크기가 동일한 버킷을 구했으므로, 각 구간의 데이터 수가 정확히 250개씩임을 확인할 수 있습니다.