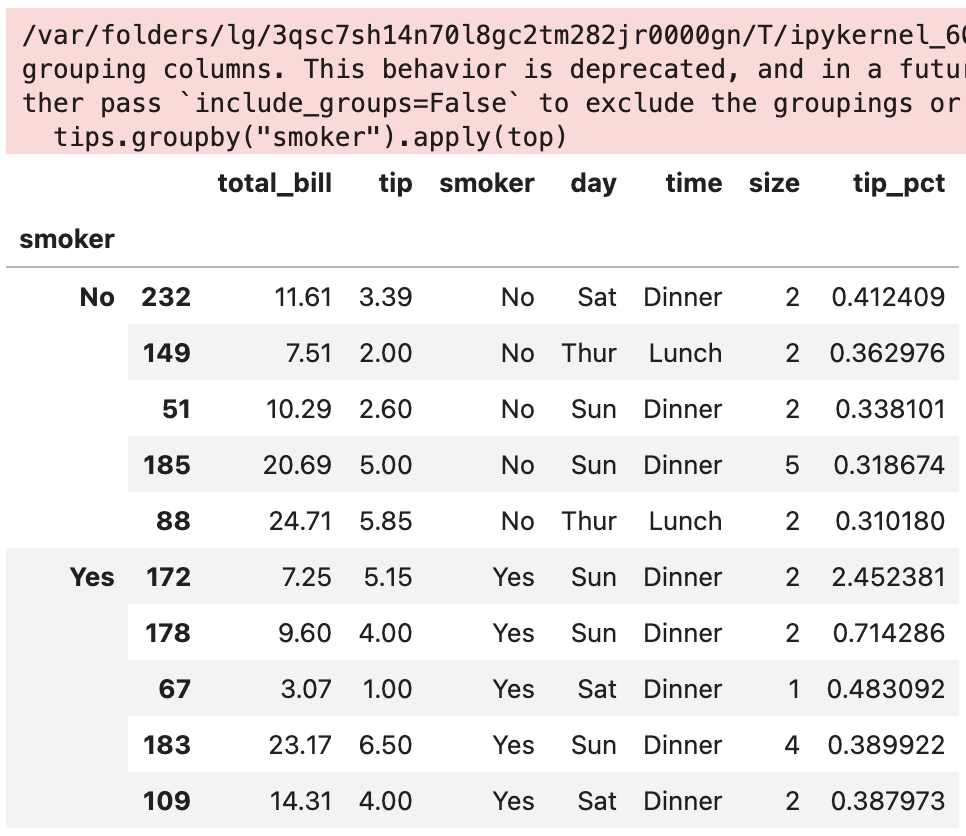
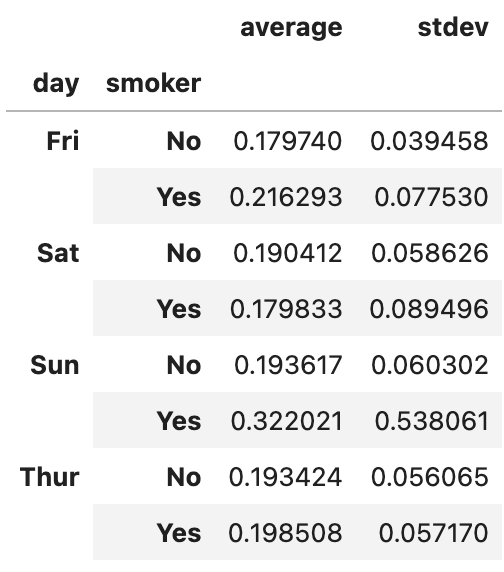
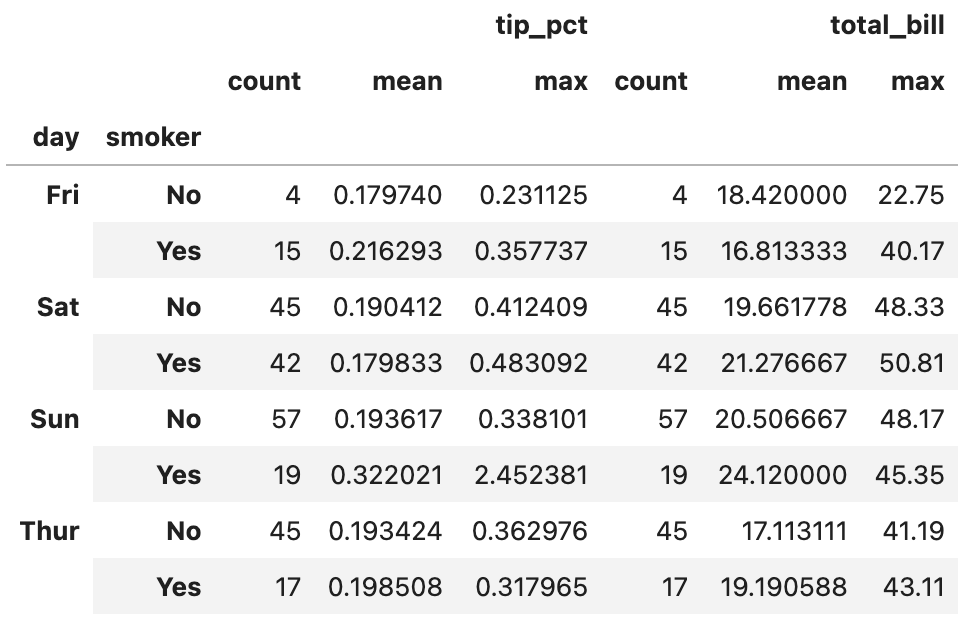
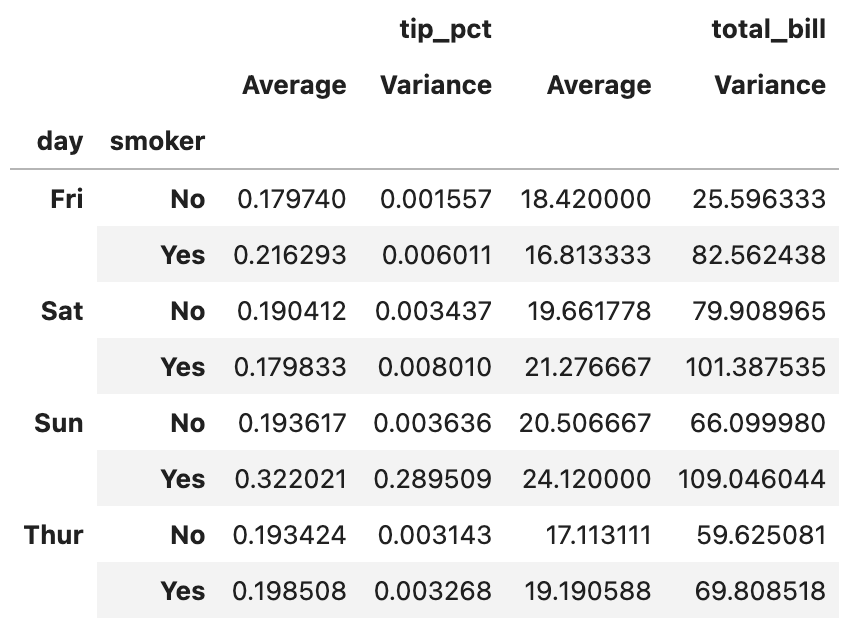
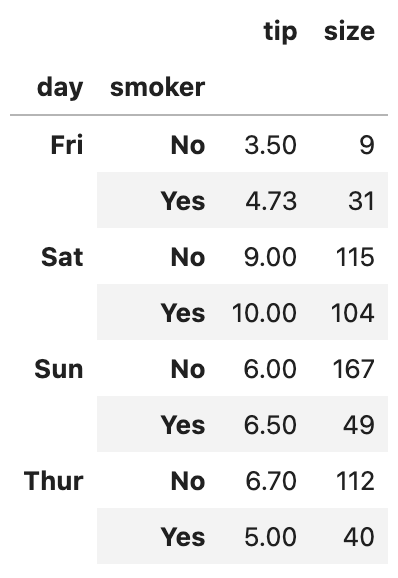
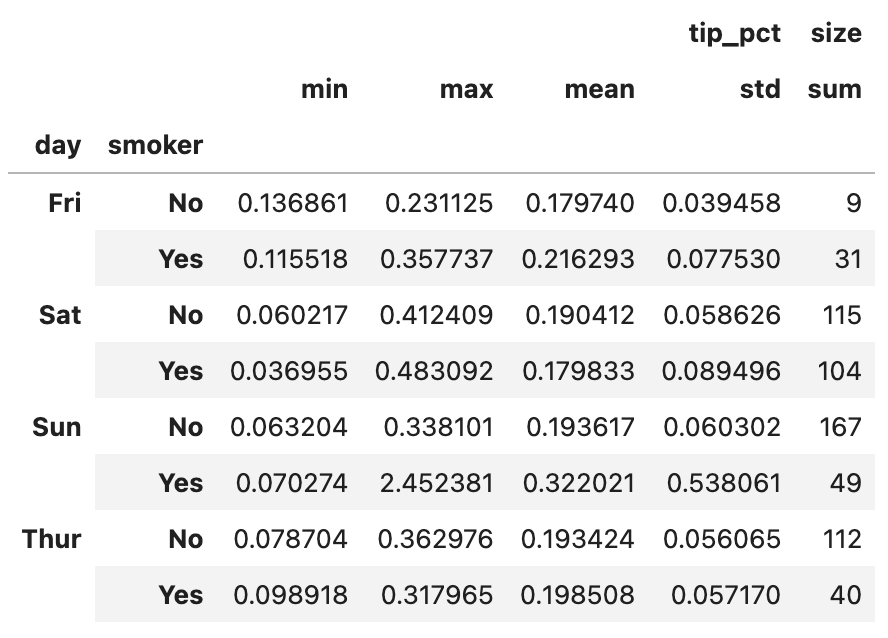
이번 포스팅에서 다룰 주제는 판다스에서 그룹별 가중평균weighted average과 상관관계correlation 구하기, 그리고 그룹별 선형회귀regression입니다.
데이터프레임에서 열 간의 연산이나 두 Series간의 연산은 일상적으로 일어나는 일이기 때문에 익혀두고 있으면 편리하겠죠? 간단한 데이터부터 예를 들어 보겠습니다.
간단한 가중평균 구하기
df = pd.DataFrame(
{
"category": ["a", "a", "a", "a", "b", "b", "b", "b"],
"data": np.random.standard_normal(8),
"weights": np.random.uniform(size=8),
}
)
df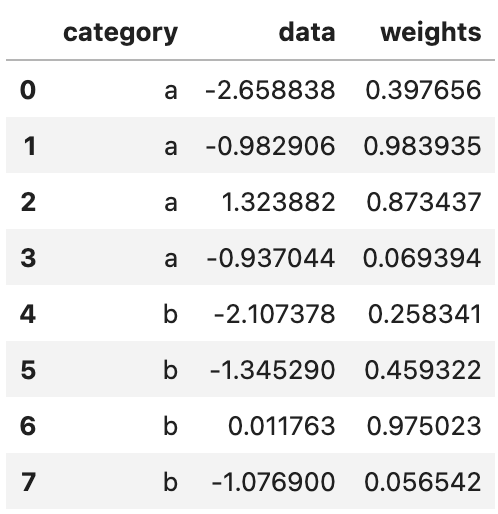
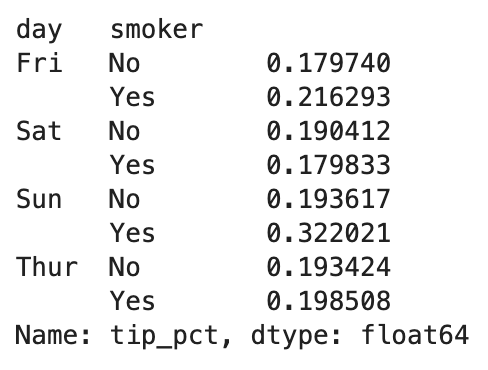
여기서 category별 가중평균을 구하는 함수를 작성해 보겠습니다.
넘파이의 average와 이전 포스팅링크들에서 계속 연습한 apply를 결합한 방식입니다.
grouped = df.groupby("category")
def get_wavg(group):
return np.average(group["data"], weights=group["weights"])
grouped.apply(get_wavg, include_groups=False)
상관관계 구하기
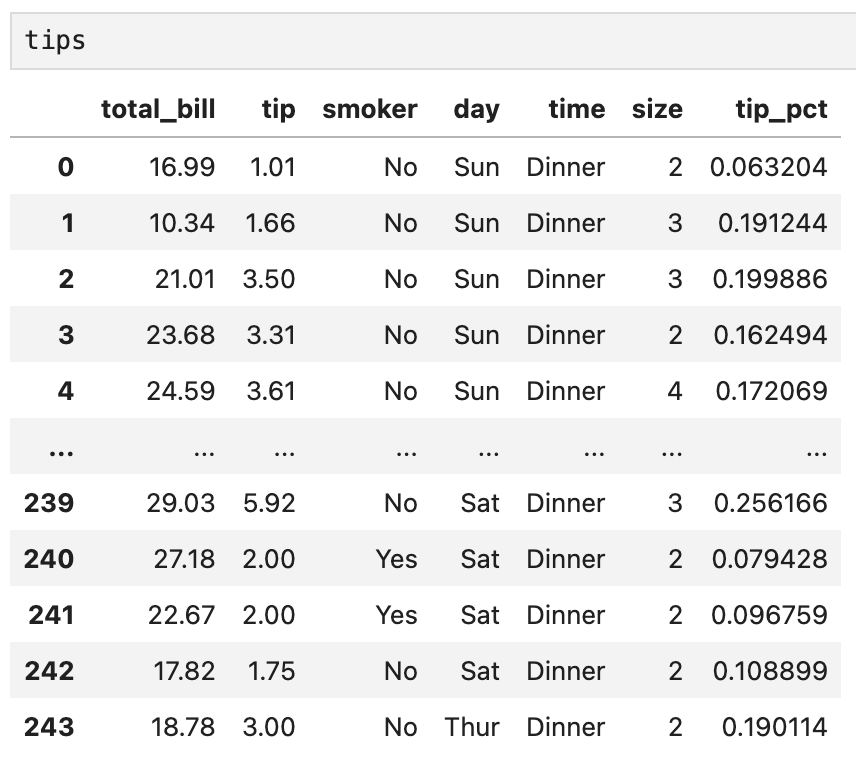
이번에는 조금 더 복잡한 예로, 야후 파이낸스에서 가져온 몇몇 주식들과 S&P500 지수(SPX)의 종가 데이터를 살펴보겠습니다.
1. 데이터 불러오기
데이터는 저자의 깃헙링크에서 다운받으실 수 있습니다.
판다스의 read_csv 명령어를 사용해 데이터를 불러오고, 정보까지 확인해 보겠습니다.
close_px = pd.read_csv("stock_px.csv", parse_dates=True, index_col=0)
close_px.info()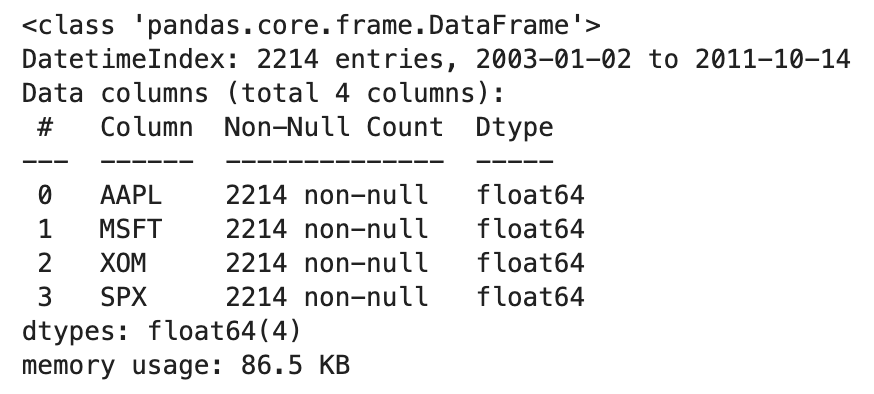
info 명령어를 써서 데이터프레임의 내용을 간략하게 살펴봅니다. 총 4개의 컬럼과 2,214개의 컬럼으로 이루어져 있고, 결측치는 없네요.
참고로 SPX를 제외한 나머지 3개 열은 순서대로 애플(AAPL), 마이크로소프트(MSFT), 엑손모빌(XOM)을 나타냅니다. 그리고 저렇게 종목명을 짧은 알파벳, 혹은 숫자 코드로 표시한 것을 티커라고 부릅니다.
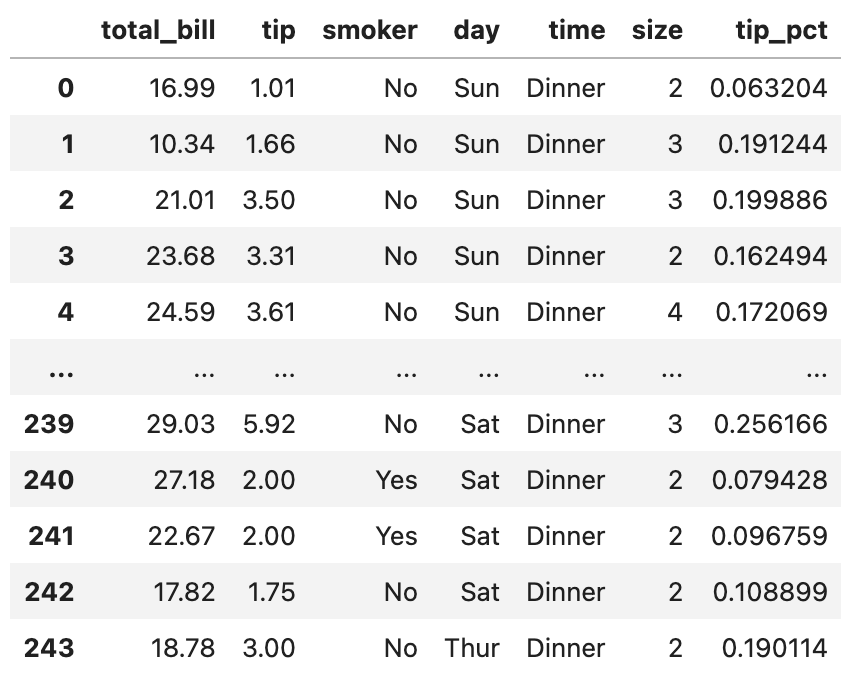
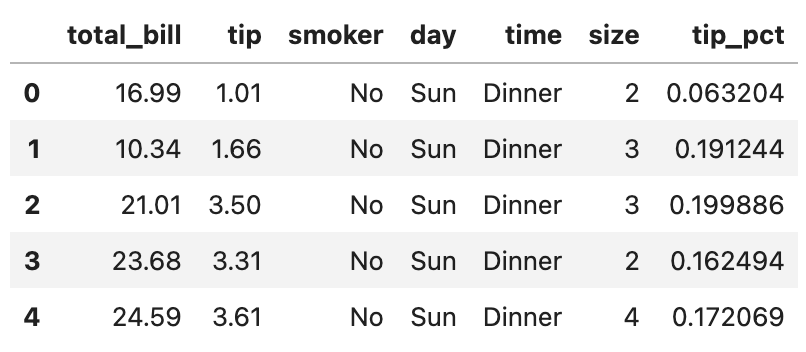
close_px.tail()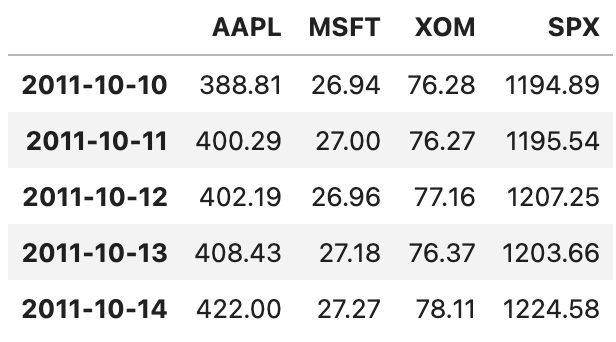
tail() 명령어를 쓰면 데이터의 마지막 5행을 불러옵니다. info에서 확인했던 대로 2011년 10월 14일까지의 데이터가 잘 들어가 있네요.
2. 상관관계를 계산하는 함수 작성하기
이제 연간 SPX 지수와 개별 종목들간의 상관관계를 살펴보겠습니다. SPX 열을 기준으로 다른 열들과의 상관관계를 계산하는 함수를 작성합니다.
def spx_corr(group):
return group.corrwith(group["SPX"])3. 각 열의 퍼센트 변화율 계산하기
이제 pct_change 함수를 이용해 close_px의 퍼센트 변화율을 계산합니다.
rets = close_px.pct_change().dropna()4. 연도별 퍼센트 변화율 구하고 상관관계 구하기
마지막으로, 각 datetime 열에서 년도만 반환하는 함수를 이용해 연도별 퍼센트 변화율을 구해봅니다.
def get_year(x):
return x.year
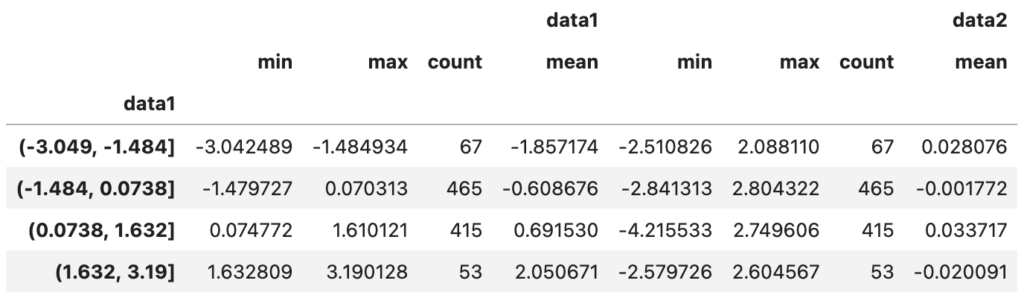
by_year = rets.groupby(get_year)by_year.apply(spx_corr)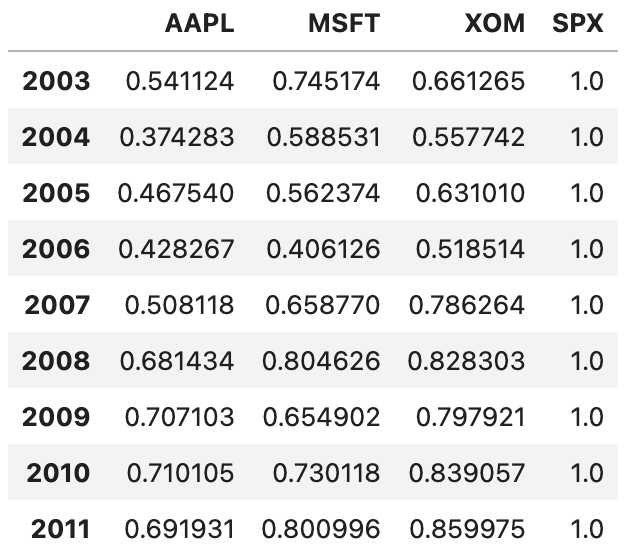
실행한 결과는 위와 같습니다.
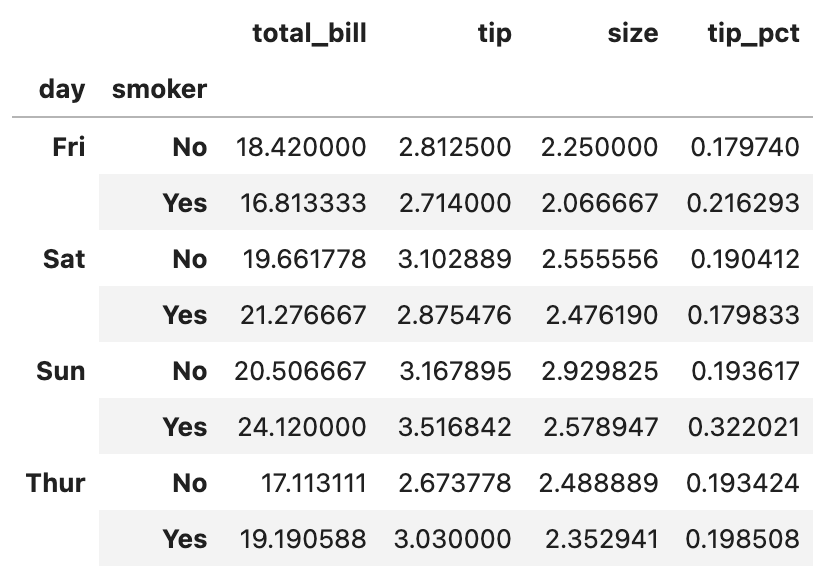
각 주식의 일자별 가격 변화율을 계산한 다음, 그 변화율이 주가지수와 어느 정도의 상관관계가 있는지를 년도별로 나타낸 결과입니다.
상관계수가 0.5에서 1 사이에 분포되어 있는 경우가 많은 것으로 보아, 대체로 주가지수의 변동과 높은 상관관계를 보이는 종목들임을 알 수 있습니다.
5. 서로 다른 두 열끼리의 상관계수 구하기
위의 예에서는 주가지수(SPX)와 다른 열 사이의 상관계수를 계산했지만, 서로 다른 두 종목끼리의 상관계수도 간단히 계산할 수 있습니다.
예를 들어 애플과 마이크로소프트의 주가 변화율의 상관관계를 보고 싶다면, 아래와 같이 함수를 작성하고 apply하면 됩니다.
def corr_aapl_msft(group):
return group["AAPL"].corr(group["MSFT"])
by_year.apply(corr_aapl_msft)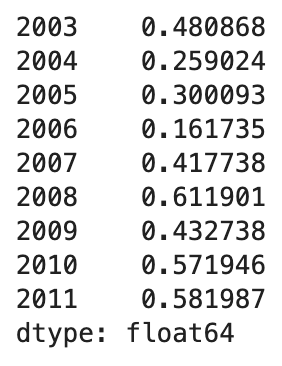
결과는 위와 같습니다.
(상관관계 심화) 그룹별 선형회귀
함수가 판다스 객체가 스칼라를 반환하기만 한다면, groupby 객체를 좀 더 복잡한 통계분석을 위해 사용할 수도 있습니다.
예컨대 계량경제 라이브러리인 statsmodels를 사용하면 각 데이터 묶음에 대해 최소자승법으로 그룹별 선형회귀를 수행할 수도 있는데요.
위에서 봤던 주가 데이터를 다시 한 번 예로 들어 보겠습니다.
먼저 statsmodels 모듈을 sm이라는 이름으로 불러오고, 이를 활용해 회귀를 수행하는 함수를 만들어 보겠습니다.
import statsmodels.api as sm
def regress(data, yvar=None, xvars=None):
Y = data[yvar]
X = data[xvars]
X["intercept"] = 1.0
result = sm.OLS(Y, X).fit()
return result.paramssm.OLS(Y, X)를 통해 OLS(Ordinary Least Squares), 즉 최소제곱법 회귀 모델을 생성했습니다. fit() 메서드는 데이터를 모델에 맞춰 추정한다는 의미를 갖고 있습니다.
결과물 result의 param 속성은 각 독립변수와 상수항에 대한 추정회귀계수를 담고 있습니다. 이제 이 모델을 SPX 수익률에 대한 애플(AAPL) 주식의 선형회귀는 아래와 같이 수행할 수 있습니다.
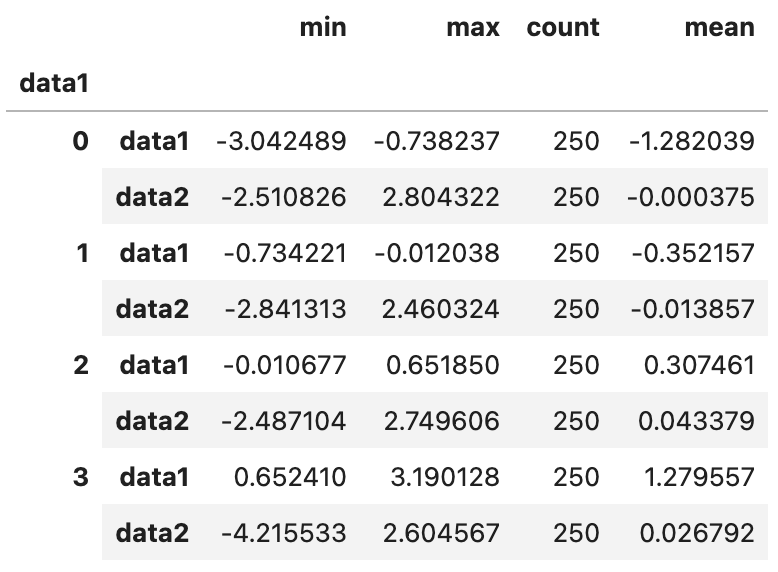
by_year.apply(regress, yvar="AAPL", xvars=["SPX"])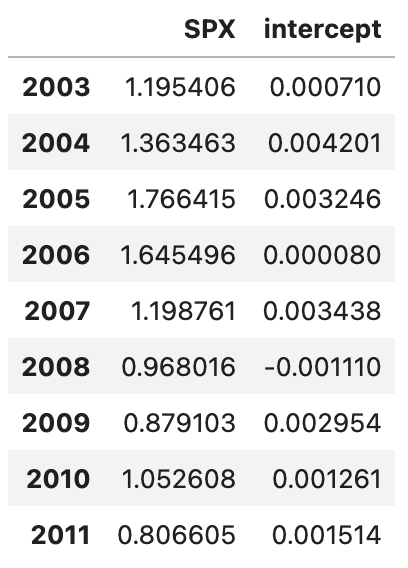
각 연도별로 AAPL과 SPX간의 선형 관계를 분석한 회귀 계수를 보여주는 결과가 생성되었습니다. 이렇게 groupby 객체의 두 열 내지는 Series를 가지고 여러 가지 복잡한 연산을 수행할 수 있습니다.